前言
隨著 LLM 模型熱潮越來越大,我們也使用越來越多的 AI 來幫助自己,不論是工作或是日常都能起到某些作用。但是我們都一直在使用別人的資源,有沒有可能我們能自己跑呢?
可以的,今天這篇文章就會來說說如何在本地跑 LLM 模型。不過前提,你的電腦可能要相對強壯一點,我自己是用 RTX 3070,都覺得有些吃力了,請自己慎重考慮。
安裝 Ollama
首先我們需要先安裝 Ollama 這套軟體,在這次的文章中會在 Windows 平台上執行。
我們先到 首頁 並點擊 Download 下載這個軟體。
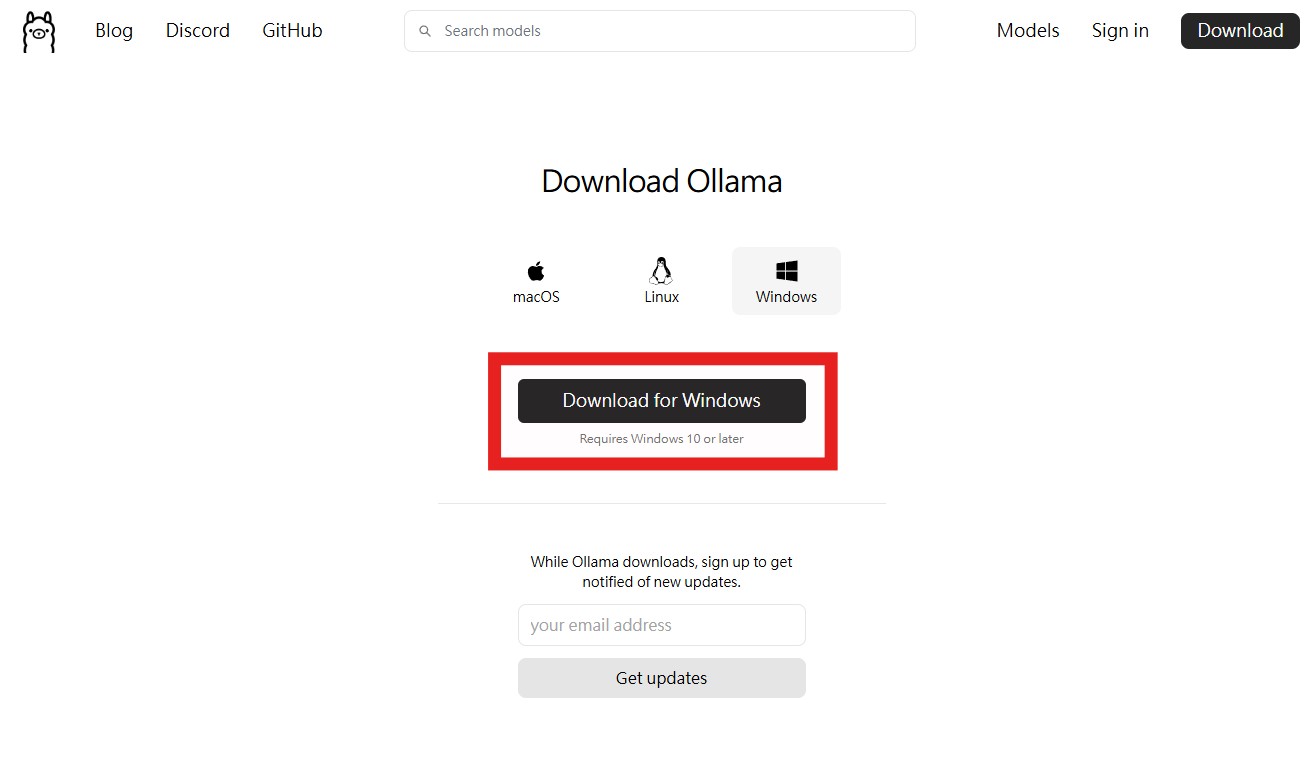
下載完後安裝他就好囉。
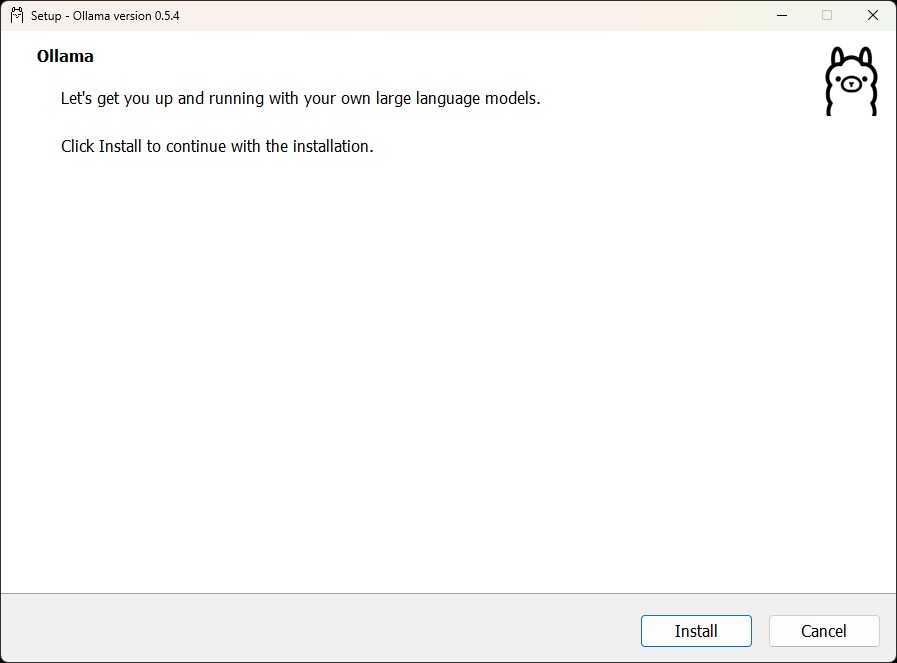
安裝模型
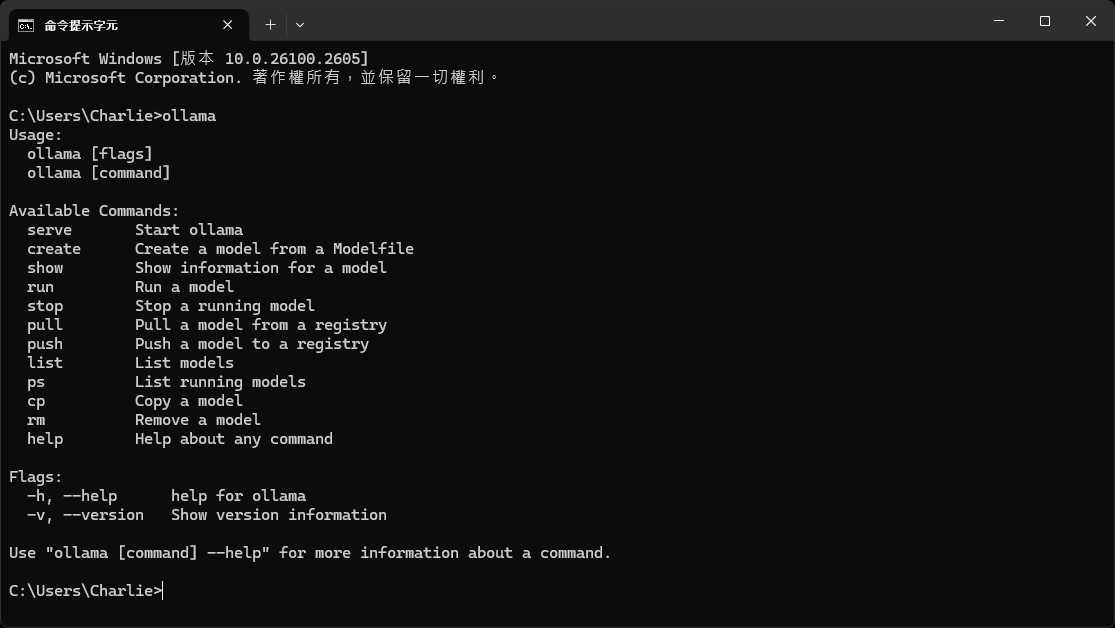
完成後,我們可以使用 Win + R 執行 cmd,輸入 ollama 並按下 Enter,你應該可以看到 Ollama 的命令們,這代表你已經順利安裝 Ollama 了。
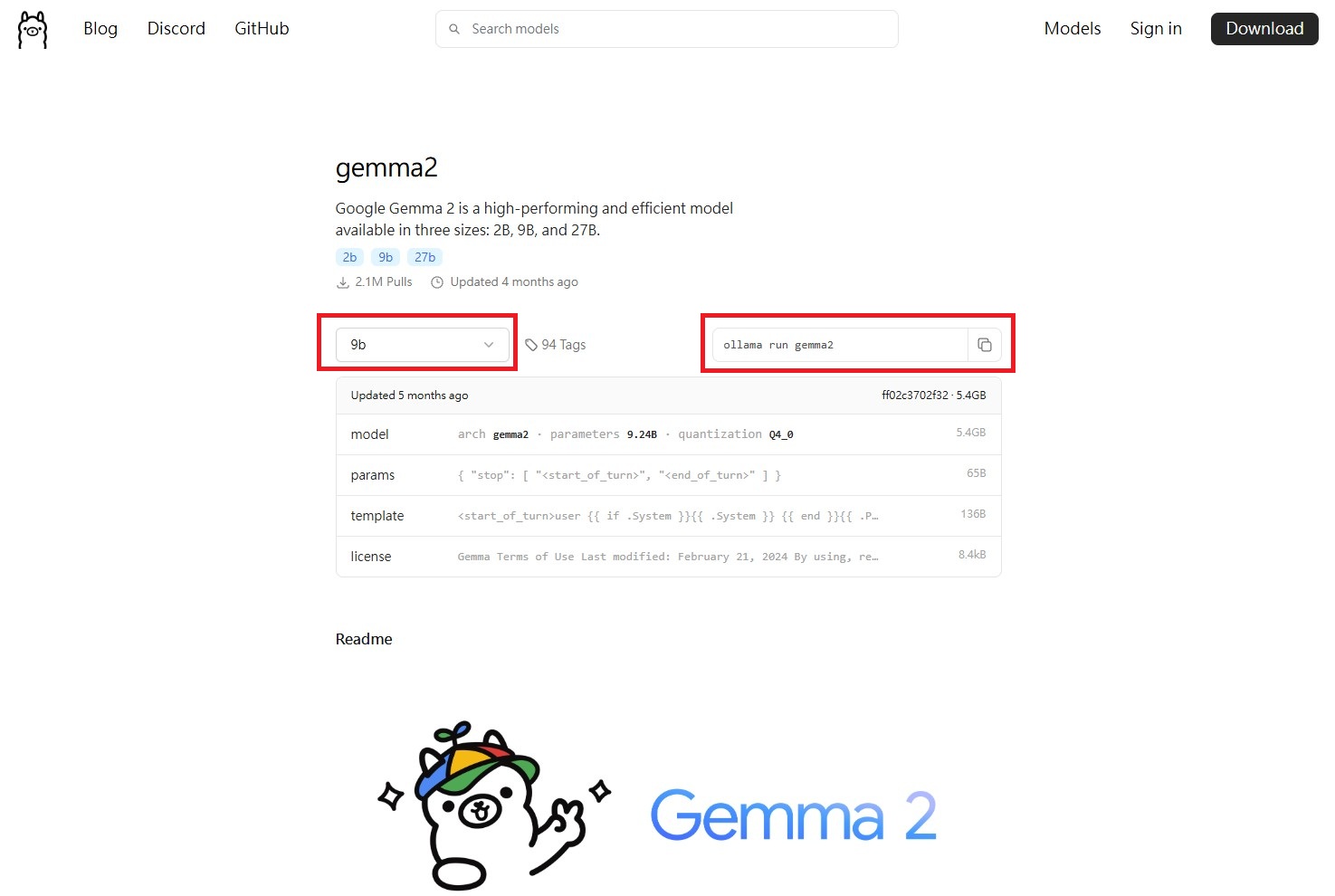
接著前往 Ollama 的 模型列表,來選擇你想使用哪個模型。例如 Meta 的 Llama、Google 的 Gemma 或是 Microsoft 的 Phi。
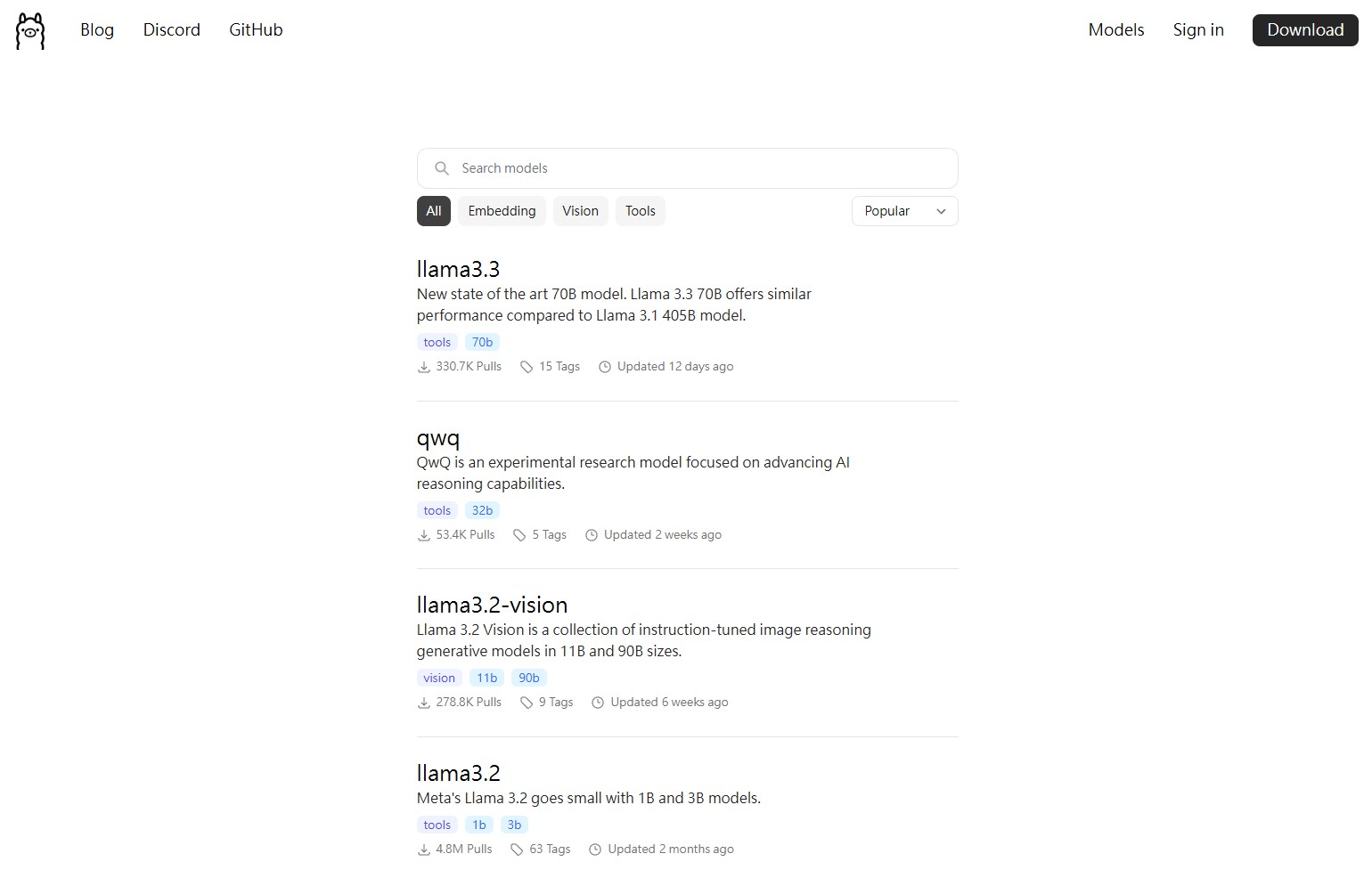
例如我這邊使用 gemma2,你可以在左邊的下拉式選單選擇模型大小,當然越大的模型就會越吃重資源,選擇完後可以在右邊看到命令,將他複製回去 cmd 內執行。
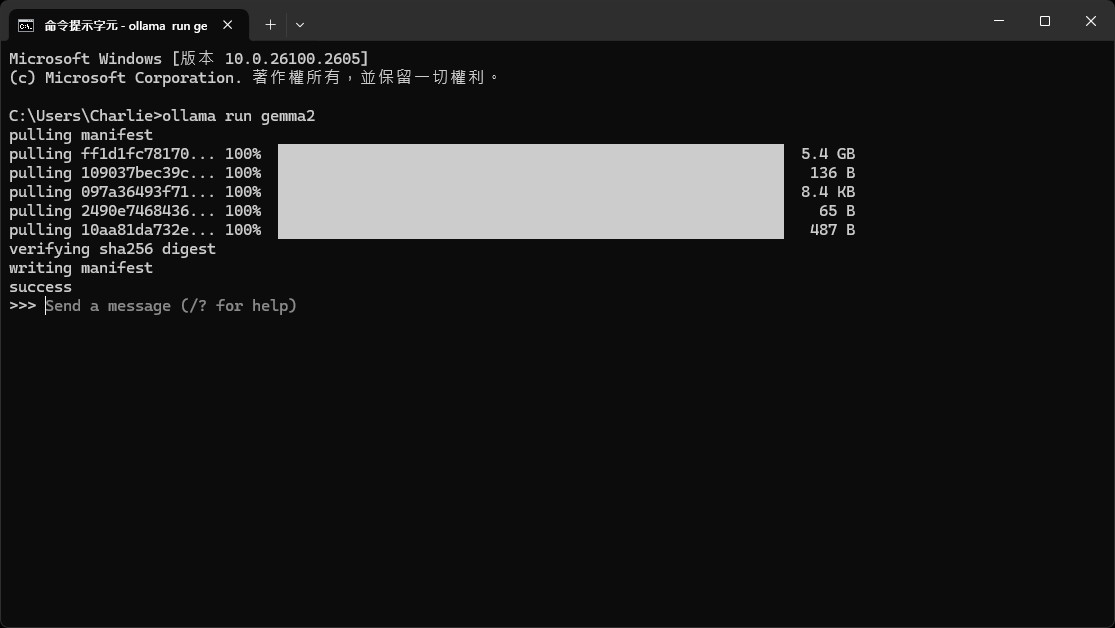
在 cmd 執行完後,當出現 Send a message 時,就代表安裝完成囉。
開始使用
現在,你可以透過 cmd 介面開始跟 LLM 模型對話了!以下就是一個範例,最後如果當你想退出的話,可以使用 /bye 退出。
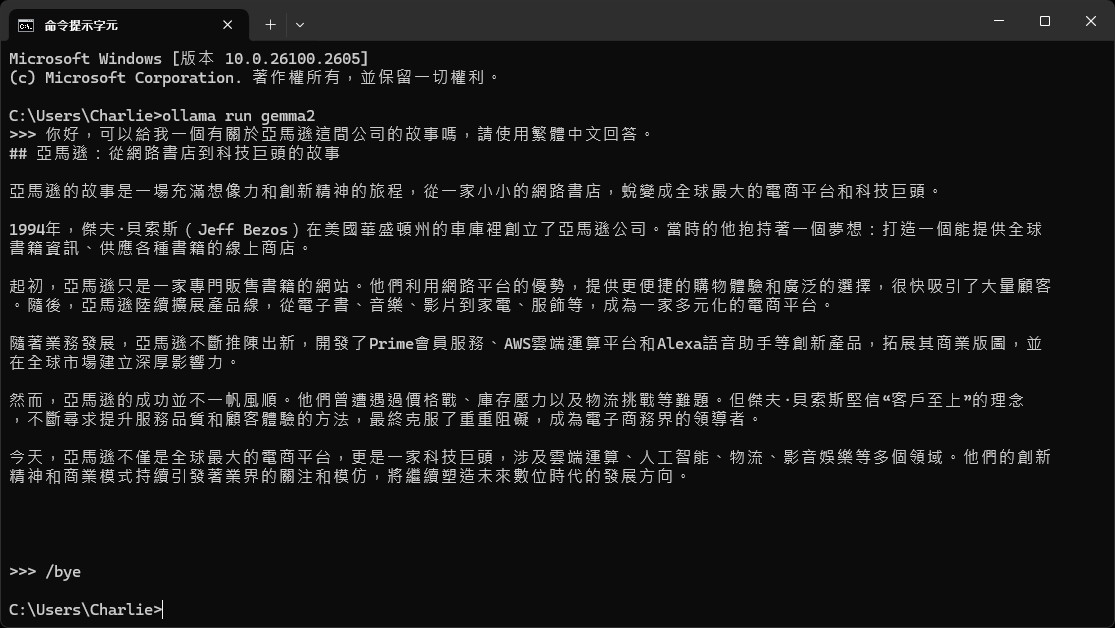
但實際上使用 /bye 不代表他真的停下來了,事實上他仍在背景運作。如果你想要他完全停下來的話,你可以使用 ollama stop 你的模型 即可。